So, I was staring at my AP Statistics textbook the other day, the one that looks suspiciously like it’s been through a war. You know the one. It’s practically a relic at this point, filled with cryptic diagrams and enough formulas to make my brain do a little happy dance of panic. Anyway, I decided, with a sigh that could rival a deflating bouncy castle, to tackle Chapter 1. And let me tell you, it felt like trying to decipher ancient hieroglyphics.
Chapter 1. AP Statistics. Just the phrase itself can send shivers down some spines, right? It’s the gateway, the first hurdle, the “what have I gotten myself into?” moment. But fear not, fellow statistical adventurers! Because after a deep dive (and maybe a few cups of coffee), I’ve emerged with some insights into those elusive Chapter 1 practice test answers. Think of this as your friendly, slightly bewildered guide through the wilderness.
We’re talking about the foundational stuff here, the ABCs of AP Stats. It’s all about understanding what data is, how to describe it, and why, oh why, we need to do it in the first place. It’s like learning your colors before you can paint a masterpiece. Except, you know, with less artistic flair and more… numbers.
Let’s dive into some of the common themes you’ll find lurking in those Chapter 1 practice tests. One of the biggest players is types of variables. Seriously, this is like the secret handshake of statistics. You’ve got your categorical variables (think things you can sort into buckets, like favorite color or type of pet) and your quantitative variables (things you can measure numerically, like height or test scores). Getting these distinctions down is key. If you mix them up, it’s like trying to bake a cake with salt instead of sugar. It just doesn’t end well.
And then there’s the whole world of displaying data. Oh, the graphs! You’ll see things like bar charts and pie charts for categorical data. They’re pretty straightforward, like looking at a visual representation of your vote count. But for quantitative data, things get a bit more interesting. We’re talking histograms, dotplots, and stemplots. These are your tools for seeing the shape of the data. Is it a bell curve? Is it skewed? Is it… lumpy? Understanding what each of these displays tells you is crucial for answering those practice questions.
I remember agonizing over a histogram question on a practice test. It showed a bunch of bars, and I had to describe its distribution. My initial thought was, “It’s… a bunch of bars.” Real helpful, right? But the key is to look for the shape, the center, and the spread. Is it symmetric? Are there any outliers? Where does the bulk of the data lie? This is where the magic happens, where you start to actually interpret the data, not just stare at it blankly.
Let’s talk about describing distributions. This is where those fancy statistical terms come into play. We’re not just talking about "high" or "low" anymore. We're using words like symmetric, skewed left, skewed right, unimodal, bimodal, and multimodal. And of course, we can’t forget outliers. These are those pesky data points that just don't seem to fit in with the rest. They can be super important, or they can be a simple typo. The practice tests often test your ability to spot them and consider their potential impact.

When you see a question asking you to describe a distribution, remember the mantra: SOCS! That’s Shape, Outliers, Center, and Spread. If you can hit all four of those points, you’re golden. Don’t just say it’s unimodal; describe where it’s unimodal. Don’t just say it has a spread; give some sense of how wide or narrow that spread is. This is where you show your understanding.
The center of the distribution is another biggie. You’ll encounter mean and median. The mean is your average, the one everyone’s probably familiar with. The median is the middle value when the data is ordered. Now, here’s a little secret weapon: the median is more resistant to outliers than the mean. So, if you have some crazy extreme values, the median might give you a better picture of the typical value. The practice tests love to throw in scenarios where you have to decide which measure of center is more appropriate. Think about that! It’s not just about calculating; it’s about choosing wisely.
And the spread? This is where range and interquartile range (IQR) come in. The range is simply the difference between the maximum and minimum values. Easy peasy. The IQR, however, is a bit more robust. It’s the difference between the third quartile (Q3) and the first quartile (Q1). It tells you about the spread of the middle 50% of your data, making it less affected by those pesky outliers. Again, knowing when to use which is a common test-prep skill.
The Mystical Five-Number Summary
Ah, the five-number summary. This is like the VIP section of describing a distribution’s center and spread. It consists of the minimum, Q1, median, Q3, and maximum. These five numbers give you a concise snapshot of your data. They’re the building blocks for things like boxplots, which are another common graphical representation you’ll encounter.
When you see a question that involves a five-number summary or a boxplot, pay close attention. What’s the range? What’s the IQR? How do the different parts of the boxplot (the whiskers, the box itself, the median line) relate to the SOCS you’re supposed to be looking for? It’s all connected, you see! It’s like a statistical puzzle.
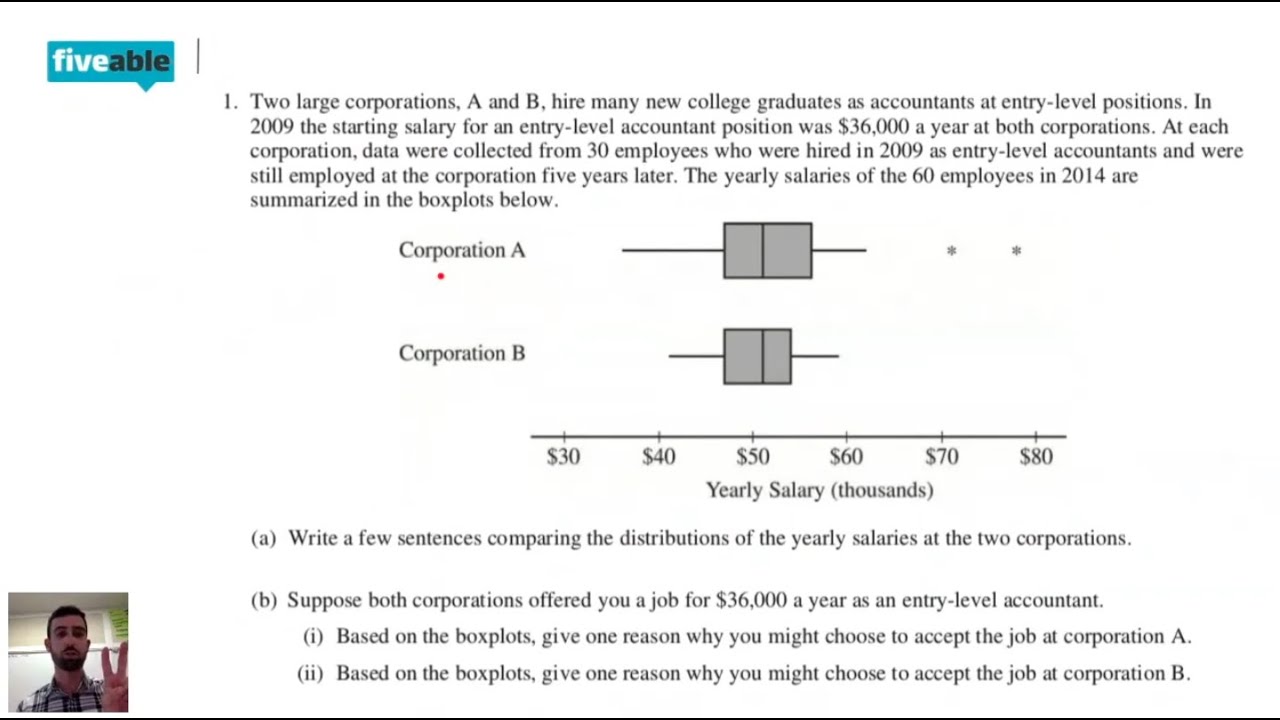
And speaking of puzzles, let’s not forget identifying potential outliers. You’ll learn about rules for this, often involving the IQR. If a data point falls too far below Q1 or too far above Q3, it’s a candidate for an outlier. The practice tests will often present a scenario and ask you to identify which value is a potential outlier. This is where you put those formulas into action – and actually use them, not just stare at them in the textbook.
The Infamous "Context is Key" Rule
One of the most important, yet sometimes overlooked, aspects of answering AP Stats questions, especially in Chapter 1, is context. You can’t just throw out numbers and labels. You need to relate everything back to the scenario. If you’re analyzing the heights of basketball players, your description should talk about heights, not just numbers. If you’re discussing test scores, make sure your interpretation makes sense in the context of academic performance.
The practice test questions are designed to see if you can translate statistical concepts into real-world meaning. So, when you’re working through those answers, always ask yourself: “What does this mean in the context of the problem?” It’s the difference between sounding like a calculator and sounding like a statistically literate human being. And honestly, who doesn't want to be a statistically literate human being? It’s a superpower, I tell you.
Another tricky area can be comparing distributions. Often, you’ll be presented with two or more datasets and asked to compare their centers, shapes, and spreads. This is where your SOCS mantra gets a workout. You need to be able to articulate how the distributions differ. Is one centered higher than the other? Is one more spread out? Does one have a different shape?

The wording of these comparison questions can be subtle. They might ask you to identify which group has a higher median or which group has a larger IQR. Don’t just state the numbers; make a direct comparison. “Group A has a higher median height than Group B, indicating that the typical height in Group A is greater.” See? Clear, concise, and contextual.
And for those of you who are already feeling a little overwhelmed (I’ve been there, my friends, I’ve been there), remember that practice tests are your friends. They’re not there to judge you; they’re there to help you identify your weak spots before the real exam. So, if you’re consistently getting questions wrong about identifying the median, that’s a clear signal to go back and review that concept. Don’t just look at the answer and say, “Oh, okay.” Try to understand why that’s the answer.
Think of it this way: each practice test question you nail is like a little victory. Each one you struggle with is an opportunity to learn. And by the time you’ve worked through enough Chapter 1 practice tests, those seemingly cryptic answers will start to make perfect sense. You’ll be able to look at a histogram and immediately know what to say about its shape, center, and spread. You’ll be able to spot outliers with the best of them.
Let’s touch on some specific types of questions you might see in Chapter 1 practice tests. You’ll probably encounter questions that involve calculating basic descriptive statistics yourself. This means you might need to find the mean, median, range, or IQR of a given dataset. Don’t shy away from the calculations; they’re fundamental. Sometimes, a simple calculation is the key to unlocking the rest of the problem.
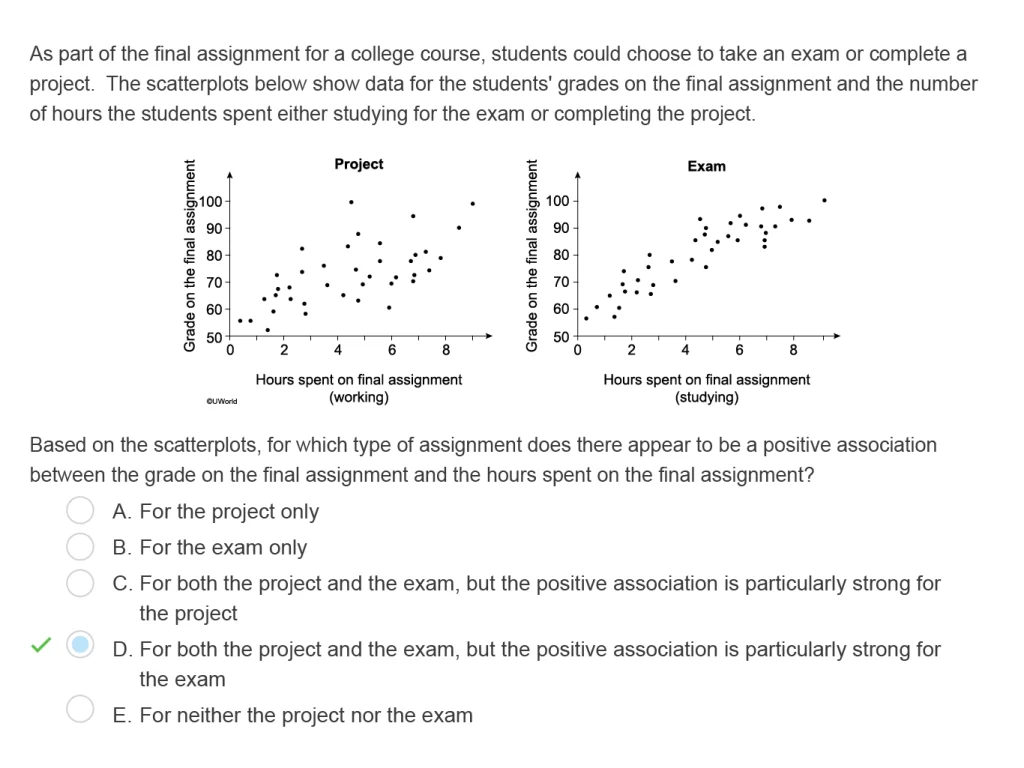
There will also be questions where you are given a graph or a table and asked to interpret it. This is where your understanding of visual representations and your ability to describe distributions come into play. Pay close attention to the labels on the axes and the units of measurement. These are not just decorative; they are essential for correct interpretation.

And then there are the conceptual questions. These test your understanding of statistical vocabulary and principles. For example, you might be asked to define what a quantitative variable is, or to explain the difference between the mean and the median in terms of resistance to outliers. These questions are crucial for building a strong theoretical foundation.
I always found it helpful to create my own little cheat sheets or summary notes as I worked through the practice tests. For Chapter 1, this might include definitions of key terms, formulas for calculating measures of center and spread, and a checklist for describing distributions (hello, SOCS!). When I could accurately fill out these summaries without peeking, I knew I was making progress.
Don’t be afraid to get your hands dirty with the data. If a practice test question involves a small dataset, try arranging it yourself, calculating the median, finding the quartiles. The more hands-on you are, the more you’ll internalize the concepts. It’s like learning to ride a bike; you can read all about it, but until you actually get on and pedal, it doesn’t quite click.
And for goodness sake, read the question carefully. I can’t tell you how many times I’ve gotten an answer wrong because I misread a keyword or overlooked a crucial detail in the prompt. AP Statistics questions are often designed to be precise, and a small oversight can lead you down the wrong path.
So, as you navigate those Chapter 1 AP Statistics practice test answers, remember: it’s a journey. It’s about building a solid foundation. It’s about understanding the language of data. And with a little bit of perseverance, a dash of curiosity, and a whole lot of practice, you’ll be decoding those statistical mysteries like a seasoned pro. Now go forth and conquer Chapter 1!